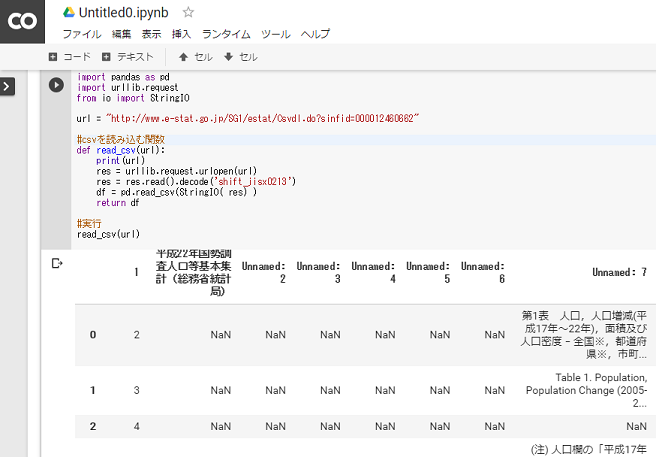
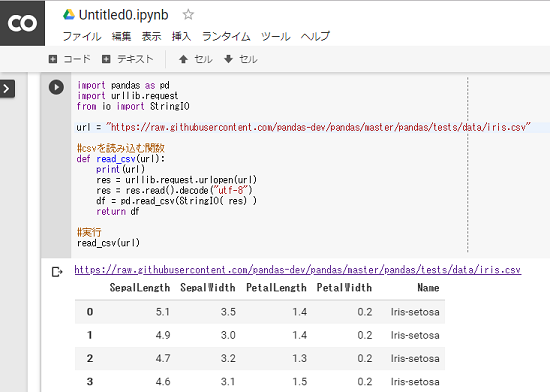
はじめに
ディープラーニング(深層学習)の理解もまだ進んでいないわけですが、今回は勝手に古い技術と思い込み何も理解しようとすらしていなかった サポートベクターマシン(Support Vector Machine:SVM)に着目してみます。
サポートベクターマシンとは
サポートベクターマシン(Support Vector Machine:SVM)は、1995年頃にAT&TのV.Vapnik(ウラジミール・ヴァプニーク(Vladimir Vapnik;1936-))が発表したパターン識別用の教師あり機械学習方法であり、局所解収束の問題が無い長所がある。「マージン最大化」というアイデア等で汎化能力も高め、現在知られている方法としては、最も優秀なパターン識別能力を持つとされている。
参照:サポートベクターマシン(SVM)
機械学習には大きく分けて「識別関数」「識別モデル」「生成モデル」の3つの種類があります。このなかで識別関数が確率を使わないので初心者が入門するのに最適です。
識別問題には線形分離可能と線形分離不可能がある。

パーセプトロンという基礎的な識別関数の学習手法は、誤差関数の勾配を利用してどんどん誤差関数を小さくしていくというものであるが、この手法には下記の2点の課題がある。
- モデルの汎化能力が保証されない。
- 線形分離可能な問題で利用できない。
SVMは2クラスの分類を行うための機械学習の手法で、大雑把に言うとパーセプトロンという基礎的な識別関数に「マージン最大化」と「カーネル関数」という考え方を導入して上記の課題に対応したものである。
マージン最大化
学習データの中で最も他クラス と近い位置にいるもの(サポー トベクタ)を基準として、その ユークリッド距離が最大になる ように識別面を決める。
汎化能力とは学習時に与えられた訓練データだけに対してだけでなく、未知の新たなデータに対するクラスラベルや関数値も正しく予測できる能力のことを指す。 そもそも、単純パーセプトロンのような機械学習を利用する目的は、スパムメールの例であれば、学習では使っていないメールでも上手くスパムかどうかを分類することである。 決して、以前にきたことのあるメールだけを分類すればいいというわけではない。
カーネルトリック
カーネルトリックとは、元々のデータ空間から高次元空間にデータを写像し、その高次元空間上で線形データ解析を行うことを指す。
ソフトマージンで線形分離不可能な場合でも、分離超平面を決定することができますが、 所詮線形分離なので、性能には限界があります。 カーネルトリックはその限界を取り払い、SVMが注目されるきっかけを作った手法です。
SVMの利点・欠点
参照:SVMってなに?
利点
- データの特徴の次元が大きくなっても識別精度が良い
- 最適化すべきパラメータが少ない
- パラメータの算出が容易
欠点
- 学習データが増えると計算量が膨大になる (「次元の呪い」の影響が顕著)
- 基本的には2クラスの分類にしか使えない
線形SVN
線形SVNは「ハードマージン」と「ソフトマージン」に分けられます。
ハードマージン
SVMはパターン認識手法の一種です。 ハードマージンSVMはその中でも一番基本となるものです。
ソフトマージン
線形分離不可能(直線では分けられない場合)にはうまく行きません。 それを解決するのがソフトマージンSVMです。
ソフトマージンSVMは、データにノイズが混じっている場合にもある程度強いという特徴があります。