はじめに
最近は、Anacodaを使わずにGoogle Colaboratoryを使用しています。
Google ChromでGoogle Colaboratory にアクセスすれば、すぐにPythonが使えますからね。
機械学習を学ぶ上では、サクッと使えるデータが必要です。
Google Colaboratoryでファイルの入出力
Google Colaboratoryでファイルの入出力については、ローカルファイルへアップロードしたり、google driveを使用する方法があります。
それらについては下記サイトを参考にするといいでしょう。
web.archive.org
qiita.com
Web上からCSVデータの読み込み
ローカルファイルへアップロードしたり、google driveを使用することすら面倒くさいと思っていて、既にWeb上に置いてあるデータをそのまま使えれば楽ちんだよね。
下記サイトを参考にしたら、統計表一覧 政府統計の総合窓口 GL08020103 のcsvデータが読めました。
blog.neko-ni-naritai.com
import pandas as pd import urllib.request from io import StringIO url = "http://www.e-stat.go.jp/SG1/estat/Csvdl.do?sinfid=000012460662" #csvを読み込む関数 def read_csv(url): print(url) res = urllib.request.urlopen(url) res = res.read().decode('shift_jisx0213') df = pd.read_csv(StringIO( res) ) return df #実行 read_csv(url)
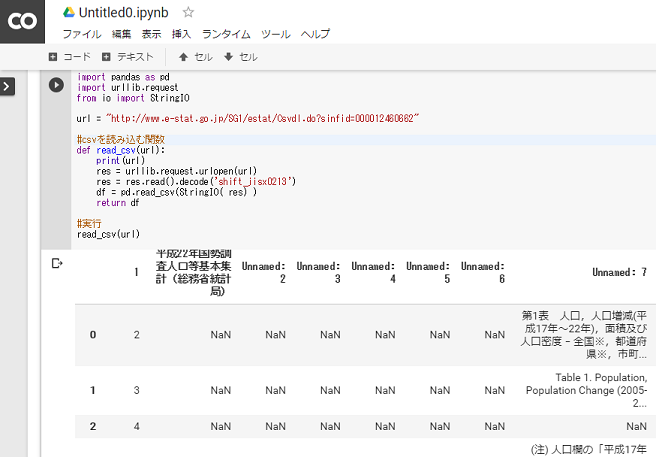
では、誰かがあげてあるGitHubのデータも使えるんじゃないかと、機械学習の初心者が学ぶ際に使用する有名なデータのアヤメ(iris)を検索して一番最初に出てきたのを使用しました。
https://github.com/pandas-dev/pandas/blob/master/pandas/tests/data/iris.csv
先程のプログラムのURLを書き換えただけだと、「ParserError: Error tokenizing data. 」となりました。
url = "https://github.com/pandas-dev/pandas/blob/master/pandas/tests/data/iris.csv"
下記記事は、R言語ですがPyhtonでも似たようなものだろうと、Raw つまり データだけが表示されるページにアクセスすればいいようです。 web.archive.org
先程のgithubのサイトに「Raw」ボタンがあったので、そこをクリックした際のURLに書き換えます。また、デコードをSJISからUTF-8に変更します。
import pandas as pd import urllib.request from io import StringIO url = "https://raw.githubusercontent.com/pandas-dev/pandas/master/pandas/tests/data/iris.csv" #csvを読み込む関数 def read_csv(url): print(url) res = urllib.request.urlopen(url) res = res.read().decode("utf-8") df = pd.read_csv(StringIO( res) ) return df #実行 read_csv(url)
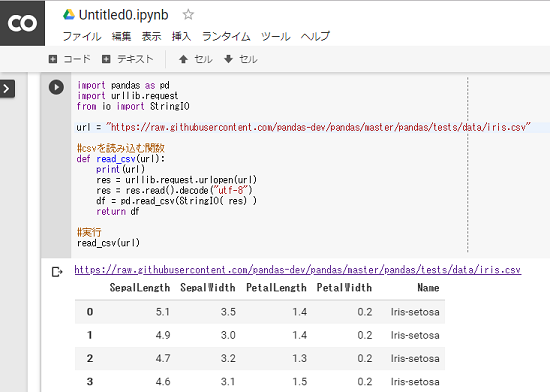
最後に
自分は面倒くさがり屋です、この「面倒くさがり屋」とはプログラマの三大美徳である「怠惰」「短気」「傲慢」の「怠惰」に匹敵する言葉だったりします。
機械学習を学ぶ上で少しでも敷居を下げれればと思います。